

python爬虫开发与项目实战是一本Python爬虫开发实战手册,由范传辉编著。本书从Python和Web前端基础开始讲起,由浅入深,包含大量案例,实用性极强。全书共有9个爬虫项目,以系统的实战项目为驱动,由浅及深地讲解爬虫开发中所需的知识和技能。从静态网站到动态网站,从单机爬虫到分布式爬虫,既包含基础知识点,又讲解了关键问题和难点分析,包含从入门到进阶的所有知识。读者认真学习完本书之后不再是个菜鸟,可以自主地开发Python爬虫项目。
内容介绍
随着大数据时代到来,网络信息量也变得更多更大,基于传统搜索引擎的局限性,网络爬虫应运而生,《python爬虫开发与项目实战》从基本的爬虫原理开始讲解,通过介绍Pthyon编程语言和Web前端基础知识引领读者入门,之后介绍动态爬虫原理以及Scrapy爬虫框架,最后介绍大规模数据下分布式爬虫的设计以及PySpider爬虫框架等。
主要特点:
由浅入深,从Python和Web前端基础开始讲起,逐步加深难度,层层递进。
内容详实,从静态网站到动态网站,从单机爬虫到分布式爬虫,既包含基础知识点,又讲解了关键问题和难点分析,方便读者完成进阶。
实用性强,本书共有9个爬虫项目,以系统的实战项目为驱动,由浅及深地讲解爬虫开发中所需的知识和技能。
难点详析,对js加密的分析、反爬虫措施的突破、去重方案的设计、分布式爬虫的开发进行了细致的讲解。
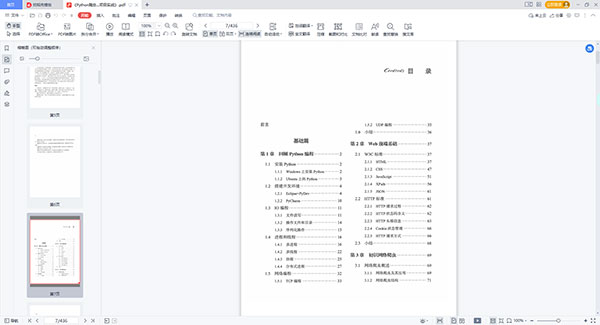
章节目录
前言 基础篇 第1章 回顾Python编程 2 1.1 安装Python 2 1.1.1 Windows上安装Python 2 1.1.2 Ubuntu上的Python 3 1.2 搭建开发环境 4 1.2.1 Eclipse+PyDev 4 1.2.2 PyCharm 10 1.3 IO编程 11 1.3.1 文件读写 11 1.3.2 操作文件和目录 14 1.3.3 序列化操作 15 1.4 进程和线程 16 1.4.1 多进程 16 1.4.2 多线程 22 1.4.3 协程 25 1.4.4 分布式进程 27 1.5 网络编程 32 1.5.1 TCP编程 33 1.5.2 UDP编程 35 1.6 小结 36 第2章 Web前端基础 37 2.1 W3C标准 37 2.1.1 HTML 37 2.1.2 CSS 47 2.1.3 51 2.1.4 XPath 56 2.1.5 JSON 61 2.2 HTTP标准 61 2.2.1 HTTP请求过程 62 2.2.2 HTTP状态码含义 62 2.2.3 HTTP头部信息 63 2.2.4 Cookie状态管理 66 2.2.5 HTTP请求方式 66 2.3 小结 68 第3章 初识网络爬虫 69 3.1 网络爬虫概述 69 3.1.1 网络爬虫及其应用 69 3.1.2 网络爬虫结构 71 3.2 HTTP请求的Python实现 72 3.2.1 urllib2/urllib实现 72 3.2.2 httplib/urllib实现 76 3.2.3 更人性化的Requests 77 3.3 小结 82 第4章 HTML解析大法 83 4.1 初识Firebug 83 4.1.1 安装Firebug 84 4.1.2 强大的功能 84 4.2 正则表达式 95 4.2.1 基本语法与使用 96 4.2.2 Python与正则 102 4.3 强大的BeautifulSoup 108 4.3.1 安装BeautifulSoup 108 4.3.2 BeautifulSoup的使用 109 4.3.3 lxml的XPath解析 124 4.4 小结 126 第5章 数据存储(无数据库版) 127 5.1 HTML正文抽取 127 5.1.1 存储为JSON 127 5.1.2 存储为CSV 132 5.2 多媒体文件抽取 136 5.3 Email提醒 137 5.4 小结 138 第6章 实战项目:基础爬虫 139 6.1 基础爬虫架构及运行流程 140 6.2 URL管理器 141 6.3 HTML下载器 142 6.4 HTML解析器 143 6.5 数据存储器 145 6.6 爬虫调度器 146 6.7 小结 147 第7章 实战项目:简单分布式爬虫 148 7.1 简单分布式爬虫结构 148 7.2 控制节点 149 7.2.1 URL管理器 149 7.2.2 数据存储器 151 7.2.3 控制调度器 153 7.3 爬虫节点 155 7.3.1 HTML下载器 155 7.3.2 HTML解析器 156 7.3.3 爬虫调度器 157 7.4 小结 159 中级篇 第8章 数据存储(数据库版) 162 8.1 SQLite 162 8.1.1 安装SQLite 162 8.1.2 SQL语法 163 8.1.3 SQLite增删改查 168 8.1.4 SQLite事务 170 8.1.5 Python操作SQLite 171 8.2 MySQL 174 8.2.1 安装MySQL 174 8.2.2 MySQL基础 177 8.2.3 Python操作MySQL 181 8.3 更适合爬虫的MongoDB 183 8.3.1 安装MongoDB 184 8.3.2 MongoDB基础 187 8.3.3 Python操作MongoDB 194 8.4 小结 196 第9章 动态网站抓取 197 9.1 Ajax和动态HTML 197 9.2 动态爬虫1:爬取影评信息 198 9.3 PhantomJS 207 9.3.1 安装PhantomJS 207 9.3.2 快速入门 208 9.3.3 屏幕捕获 211 9.3.4 网络监控 213 9.3.5 页面自动化 214 9.3.6 常用模块和方法 215 9.4 Selenium 218 9.4.1 安装Selenium 219 9.4.2 快速入门 220 9.4.3 元素选取 221 9.4.4 页面操作 222 9.4.5 等待 225 9.5 动态爬虫2:爬取去哪网 227 9.6 小结 230 第10章 Web端协议分析 231 10.1 网页登录POST分析 231 10.1.1 隐藏表单分析 231 10.1.2 加密数据分析 234 10.2 验证码问题 246 10.2.1 IP代理 246 10.2.2 Cookie登录 249 10.2.3 传统验证码识别 250 10.2.4 人工打码 251 10.2.5 滑动验证码 252 10.3 www>m>wap 252 10.4 小结 254 第11章 终端协议分析 255 11.1 PC客户端抓包分析 255 11.1.1 HTTP Analyzer简介 255 11.1.2 虾米音乐PC端API实战分析 257 11.2 App抓包分析 259 11.2.1 Wireshark简介 259 11.2.2 酷我听书App端API实战分析 266 11.3 API爬虫:爬取mp3资源信息 268 11.4 小结 272 第12章 初窥Scrapy爬虫框架 273 12.1 Scrapy爬虫架构 273 12.2 安装Scrapy 275 12.3 创建cnblogs项目 276 12.4 创建爬虫模块 277 12.5 选择器 278 12.5.1 Selector的用法 278 12.5.2 HTML解析实现 280 12.6 命令行工具 282 12.7 定义Item 284 12.8 翻页功能 286 12.9 构建Item Pipeline 287 12.9.1 定制Item Pipeline 287 12.9.2 激活Item Pipeline 288 12.10 内置数据存储 288 12.11 内置图片和文件下载方式 289 12.12 启动爬虫 294 12.13 强化爬虫 297 12.13.1 调试方法 297 12.13.2 异常 299 12.13.3 控制运行状态 300 12.14 小结 301 第13章 深入Scrapy爬虫框架 302 13.1 再看Spider 302 13.2 Item Loader 308 13.2.1 Item与Item Loader 308 13.2.2 输入与输出处理器 309 13.2.3 Item Loader Context 310 13.2.4 重用和扩展Item Loader 311 13.2.5 内置的处理器 312 13.3 再看Item Pipeline 314 13.4 请求与响应 315 13.4.1 Request对象 315 13.4.2 Response对象 318 13.5 下载器中间件 320 13.5.1 激活下载器中间件 320 13.5.2 编写下载器中间件 321 13.6 Spider中间件 324 13.6.1 激活Spider中间件 324 13.6.2 编写Spider中间件 325 13.7 扩展 327 13.7.1 配置扩展 327 13.7.2 定制扩展 328 13.7.3 内置扩展 332 13.8 突破反爬虫 332 13.8.1 UserAgent池 333 13.8.2 禁用Cookies 333 13.8.3 设置下载延时与自动限速 333 13.8.4 代理IP池 334 13.8.5 Tor代理 334 13.8.6 分布式下载器:Crawlera 337 13.8.7 Google cache 338 13.9 小结 339 第14章 实战项目:Scrapy爬虫 340 14.1 创建知乎爬虫 340 14.2 定义Item 342 14.3 创建爬虫模块 343 14.3.1 登录知乎 343 14.3.2 解析功能 345 14.4 Pipeline 351 14.5 优化措施 352 14.6 部署爬虫 353 14.6.1 Scrapyd 354 14.6.2 Scrapyd-client 356 14.7 小结 357 深入篇 第15章 增量式爬虫 360 15.1 去重方案 360 15.2 BloomFilter算法 361 15.2.1 BloomFilter原理 361 15.2.2 Python实现BloomFilter 363 15.3 Scrapy和BloomFilter 364 15.4 小结 366 第16章 分布式爬虫与Scrapy 367 16.1 Redis基础 367 16.1.1 Redis简介 367 16.1.2 Redis的安装和配置 368 16.1.3 Redis数据类型与操作 372 16.2 Python和Redis 375 16.2.1 Python操作Redis 375 16.2.2 Scrapy集成Redis 384 16.3 MongoDB集群 385 16.4 小结 390 第17章 实战项目:Scrapy分布式爬虫 391 17.1 创建云起书院爬虫 391 17.2 定义Item 393 17.3 编写爬虫模块 394 17.4 Pipeline 395 17.5 应对反爬虫机制 397 17.6 去重优化 400 17.7 小结 401 第18章 人性化PySpider爬虫框架 403 18.1 PySpider与Scrapy 403 18.2 安装PySpider 404 18.3 创建豆瓣爬虫 405 18.4 选择器 409 18.4.1 PyQuery的用法 409 18.4.2 解析数据 411 18.5 Ajax和HTTP请求 415 18.5.1 Ajax爬取 415 18.5.2 HTTP请求实现 417 18.6 PySpider和PhantomJS 417 18.6.1 使用PhantomJS 418 18.6.2 运行 420 18.7 数据存储 420 18.8 PySpider爬虫架构 422 18.9 小结 423
使用说明
1、下载并解压,得出pdf文件
2、如果打不开本文件,请务必下载pdf阅读器
3、安装后,在打开解压得出的pdf文件
4、双击进行阅读
发表评论
0条评论软件排行榜
热门推荐
 未公开的Oracle数据库秘密 迪贝斯pdf扫描版34.69M / 简体中文
未公开的Oracle数据库秘密 迪贝斯pdf扫描版34.69M / 简体中文 PHP语言精粹电子书 pdf扫描版25.72M / 简体中文
PHP语言精粹电子书 pdf扫描版25.72M / 简体中文 linux常用命令大全 chm版1.48M / 简体中文
linux常用命令大全 chm版1.48M / 简体中文 本草纲目 5.34M / 简体中文
本草纲目 5.34M / 简体中文 cnki全球学术快报电脑版 v0.2.3495.79M / 简体中文
cnki全球学术快报电脑版 v0.2.3495.79M / 简体中文 网易云阅读电脑版 v6.7.0官方pc版22.7M / 简体中文
网易云阅读电脑版 v6.7.0官方pc版22.7M / 简体中文 docker入门实战 pdf完整版1.38M / 简体中文
docker入门实战 pdf完整版1.38M / 简体中文 HotSpot实战(陈涛著) 中文pdf扫描版82M / 简体中文
HotSpot实战(陈涛著) 中文pdf扫描版82M / 简体中文 吉利博瑞用户手册 pdf高清版57.89M / 简体中文
吉利博瑞用户手册 pdf高清版57.89M / 简体中文 数据挖掘导论 官方版61.61M / 简体中文
数据挖掘导论 官方版61.61M / 简体中文
 赣公网安备36010602000168号,版权投诉请发邮件到ddooocom#126.com(请将#换成@),我们会尽快处理
赣公网安备36010602000168号,版权投诉请发邮件到ddooocom#126.com(请将#换成@),我们会尽快处理