

熊猫智能采集软件是由熊猫采集官方推出的一款功能强大,但又操作简单的领先的采集器软件。它采用熊猫精准搜索引擎的解析内核,实现对网页内容的仿浏览器解析,在此基础上利用原创的技术实现对网页框架内容与核心内容的分离、抽取,并实现相似页面的有效比对、匹配。因此,用户只需要指定一个参考页面,熊猫采集软件系统就可以据此来匹配类似的页面,来实现用户需要采集资料的批量采集。
在采集过程中,用户不再需要使用非常专业的“正则表达式”技术,不要需要借助技术高手来编写采集匹配规则。熊猫采集软件系统会将参考页面的内容解析分解后,由用户利用鼠标点选需要采集的对象即可,系统据此就可以知道用户需要采集的内容。总之,浏览器可见的内容都可以采集,有兴趣的用户不妨下载体验!
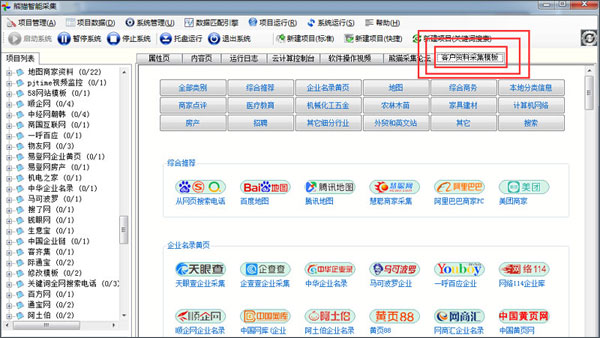
如何用熊猫采集器实现网络上企业名录、客户手机电话号码的搜索采集
1、首先,打开软件,点击“客户资料采集模板”标签。可以看到主流的电话源网站,都已经内置在软件中了,包括“从网页搜索电话”(输入关键词,即可全网搜索相关电话)。官方会不停的追加新的电话源采集网站进去。如果你有合适的网站,也可以推荐给熊猫。
电话采集模板
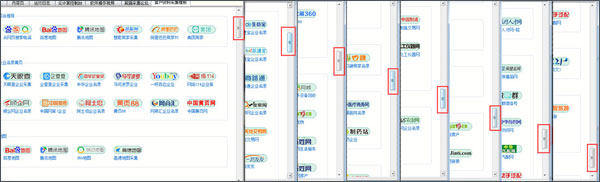
图示1:客户资料采集模板
2、点击你需要采集对象网站的图标,即可打开新项目复制对话框。
新项目复制对话框
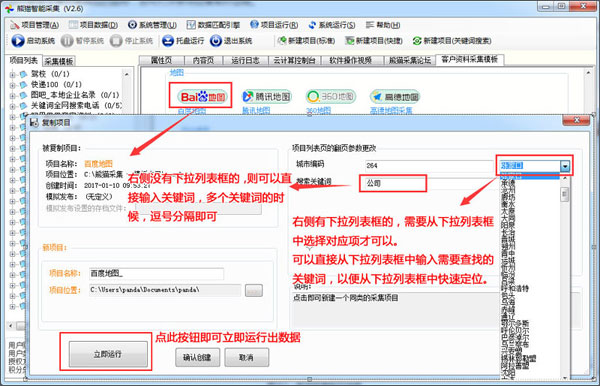
图示2:新项目复制对话框
3、在打开的复制项目对话框中,首先选择你需要采集的城市编码,从下拉列表中直接选择即可(如果下拉列表太长,难以找到。可以直接在下拉列表框中,输入你需要的城市名称,即可快速定位该城市。)。
然后输入你需要搜索的关键词,多个关键词之间可以用逗号分开即可。
再将当前项目取个名字(在上述截图左侧的“项目名称”输入框中)。
然后点击“确认创建”按钮,即可完成一个新的电话采集项目的配置。
是不是足够简单?——已经简单到无法再简单了!
然后点击“立即运行”按钮,即可关闭设置界面,直接进入数据采集运行。
最新获取的结果数据,会在软件主界面下方的列表中滚动展示:
最新获取的结果数据
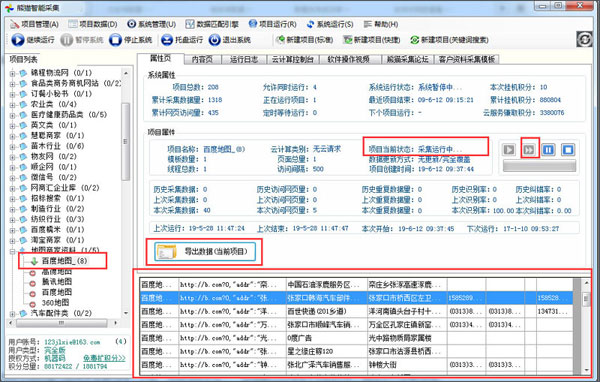
图示3:最新获取的结果数据
4、当当前项目的运行进度条全部完成,并且“项目当前状态:”出现“运行已完成”字样的时候,说明本次采集完成。
当项目运行结束后,即可选择导出数据:软件菜单:项目数据-导出数据 。(或者直接点击软件界面中间的“导出数据(当前项目)”按钮)
导出数据
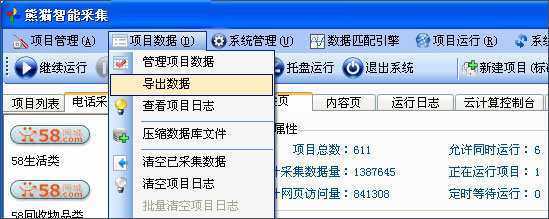
图示4:导出数据
5、默认的导出数据设置,是只导出单一的电话号码,并自动排除重复手机号。如果需要完整数据,请在弹出的对话框中,选择“指定列输出”。
导出数据的设置
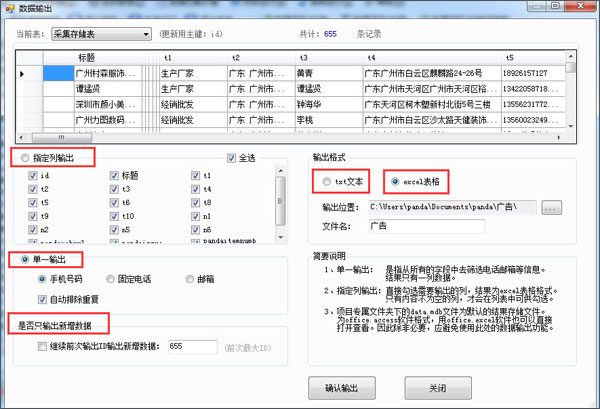
图示5:导出数据的设置
6、默认的导出数据文件,会在项目专属文件夹下,和当前项目同名的文件。
默认情况下,项目采集结果数据会存储在项目专属文件夹下的data.mdb文件中,为office.access软件格式,用office.excel软件也可以直接打开该data.mdb文件进行查看、编辑。推荐使用access软件打开该data.mdb文件进行数据输出。如果你的电脑中,没有安装Office或者access,可以使用“导出数据”功能导出为csv通用excel格式文件。
7、至此即可完成一个电话采集项目的设置、运行、数据导出的全部流程。
注意同一个网站下,不宜同时运行多个采集项目,因为这会给对方网站造成很大的访问压力,进而可能会被封IP。软件的内置模板已经对访问压力做了均衡设置,单一项目运行的时候,一般不会被封IP的。但是同时运行多个项目,则会超出均衡设置的范围。
当被封IP的时候,请打开“项目高级设置”-云计算-选择“仅请求协助网页的访问”,进行云采集,即可绕开对方网站的采集屏蔽。
项目的云采集请求的设置
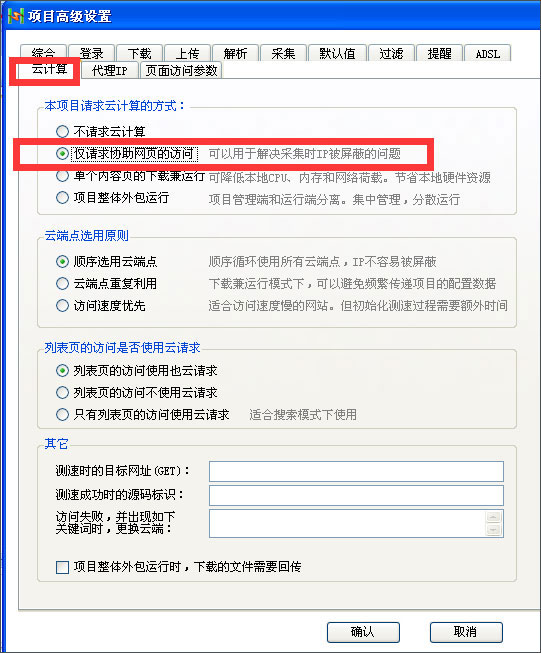
图示6:项目的云采集请求的设置
软件特色
1、全方位的采集功能
采集的对象包括文字内容、图片、flash动画视频、下载文件等等各类网络内容。支持图文混排对象的同时采集。支持结构复杂的采集对象集合,支持复杂多数据库表单,支持跨页面内容合并采集的能力。
2、面向对象采集,采集对象的内容可以是分散在多个页面(模板页面的深度嵌套访问)熊猫采集是面向对象的,一个采集对象可以拥有许多需要采集的子项属性内容。这些子项属性的内容允许分散在不同的页面内,这些页面可以是需要通过若干次链接才能到达的页面。
此处所谓“对象”,可以理解为“(需要采集的数据的)数据集合 ”的意思。这个数据集合的内容和范围由用户根据实际需求自行决定,没有特定的要求。也可以将该对象范畴囊括到“标题列表页面”,这属于变通使用的方法,在此不多做赘述。灵活的使用面向对象的方法,不仅可以实现很多复杂的采集需求,更可以使得采集设置过程更为简单。
3、采集速度快
熊猫采集的采集速度是采集软件中最快的(之一)。不使用落后低效的正则匹配技术。也不使用第三方内置浏览器访问的技术。使用自己研发的解析引擎,实现对网页源码的仿浏览器解析。分解网页可视化内容元素,在此基础上进行机器学习、批量采集匹配。经实际测试,是传统的正则匹配方式采集速度的2~5倍。是基于第三方内置浏览器采集速度的10~20倍。
4、结果数据完整度高
实际采集过程中,由于目标页面存在丰富的内容页面板式的情况,此时就需要使用熊猫独有的“多模板功能”,才能实现完整的采集。同时,看起来页面版面一致的情况下,也可能会存在因为页面内部的少量差异而采集采集匹配失败,此时就需要采集器具有智能容错能力。智能容错能力,是衡量一个采集器是否成熟的基本标志之一。熊猫追求的是采集结果100%的完整。包括有效页面100%的采集,页面中采集的内容100%的采集。只要设置恰当,不会出现采集结果遗漏的情况。——只有熊猫才能让结果如此完整。
5、JS解析的自动判断识别
现在很多网页都采用了ajax网页内容动态生成技术。此时仅仅依靠网页源码,并不能获取需要的有效内容。此时就需要对被采集的页面执行JavaScript(JS)解析,获取JS执行后的结果代码。熊猫支持对需要JS解析的页面,执行JS解析,获取JS解析后的实际内容。鉴于执行JS解析的速度效率很低,因此熊猫内置了智能判断功能,自动检查是否需要对被采集的页面执行JS解析,如果不需要的,尽量不使用低效的JS解析模式。
6、多模板自动适应能力
很多网站的“内容页面”会存在多个不同种类的模板,因此熊猫采集软件允许每个采集项目可以同时设置多个内容页面参考模板,在采集运行时,系统会自动匹配寻找最合适的参考模板用来分析内容页面。
7、实时帮助窗口
在采集项目设置环节,系统会在窗口右上显示与当前配置相关的实时帮助内容,为使用新手提供实时帮助。因此熊猫采集软件的使用可以轻松上手。配合全程智能化辅助能力,即便是第一次接触熊猫采集软件,也可以较轻松实现采集项目的配置工作。
8、正文和回复内容同时采集的能力
典型如论坛页面,正文内容在前,若干回复内容在后,或者还存在若干个回复分页存在。熊猫采集可以将这些作为一个“对象”来对待,一并同时完整采集,其配置过程也非常简单。
9、分页内容的轻松合并
支持各种类型的分页模式,用户只需要做两步就可以实现分页内容的合并:鼠标点选确认分页链接所在,将需要分页合并的字段项勾选上“分页合并”项即可。如果页面内具有重复子项存在,则能自动在分页中寻找该重复子项,隐含自动进行分页内容合并。
典型如上述的论坛例子,分页页面内的回复内容,可自动实现归并,此时用户只需要鼠标点选确认分页链接所在即可。有些场合下,在论坛内容页面的分页中也会同时出现主体(主表)内容,此时系统会自动进行判断,不会将主表内容当成重复子项的子表内容进行采集。
10、利用cookie方式模拟登录网站
对于需要登录才能访问采集页面的网站(包括Discuz等各类型论坛),可以利用账号进行模拟登录。熊猫采集可以通过模拟浏览器机制,利用动态cookie和网站进行cookie动态对话。有些网站,为了加强数据的安全性,利用cookie对网页内容数据进行加密,此时就需要使用熊猫采集特有的“动态Cookie”功能。
11、支持常见类型数据库引擎。支持FTP上传
熊目前版本的熊猫,支持Access/mssql/mysql/Oracle 四种常用数据库类型,以后可能会视需求进行扩充。支持将下载的各类文件图片等同时FTP上传到远程服务器内。用户利用此项功能就可以将在本地电脑上采集的数据同时更新到自己网站内,充实栏目内容。对于其他的动态数据发布方式,熊猫会在用户使用反馈的基础上尽快实现。
12、无人值守自动定时运行
提供更新采集访问的能力,自动定时更新运行。无需人工干预,系统自动封闭运行。
13、文字内容的“伪原创”修改。支持文章时间的提前
提供文字内容的“伪原创”修改。还可以将文章时间做“提前”修改,文章的发表时间是搜索引擎用来区别文章是否原创的一个参考因素。
软件功能
1、大数据采集
熊猫拥有极高的采集速度和效率,是大数据采集场合的最优选择。同时熊猫独有的海量数据处理能力,可以应付大数据采集的需要。是大数据采集场合的首选
2、舆情监测
借助全部中文搜素引擎,轻松实现全网舆情信息的监测,信息覆盖面广。对于需要重点监测的网站,只需要录入网址即可实现监测。PC端独立运行,普通的移动PC即可胜任舆情监测工作。同时熊猫智能采集监测引擎,也是第三方舆情系统内置爬虫的首选。
3、招标信息监测
利用熊猫智能采集监测引擎,可以轻松实现对招标信息发布网站的最新招标信息进行监测。熊猫采集,是招标信息监测软件的最优选择:操作容易、维护简单、结果直观方便。
4、客户资料收集
利用熊猫可以轻松从网络中批量获取需要的客户信息,利用熊猫的各类绕开防采集机制(,如熊猫独有的云采集功能),可以轻松绕开被采集网站的防采集机制。如58、赶集、百姓网、阿里巴巴、慧聪等等。
5、众多站长:网站搬家、网站内容自动填充
熊猫是操作最简单的采集器,是众多网站站长的首先。同时熊猫也是功能复杂的采集器,可以应用几乎所有的复杂网站的采集、搬家操作。
6、采集互联网资源
利用熊猫采集软件,可以将互联网资源实现批量、格式化的下载到本地。 可选的采集工具软件是在太多了,但都属于DOS时代,操作繁琐、作用简单、需要专业技术人员才可以勉强操作。而熊猫不同,全程可视化鼠标操作,操作简单,且功能全面,尤其熊猫可以实现非常复杂的采集需求,不懂技术的人也可以轻松操作。熊猫采集是采集软件的换代产品,——轻松采集,从熊猫开始!
7、充实用户网站内容
用户可以利用熊猫,将互联网上零散或集中的资源批量采集拷贝到自己网站内,充实自己网站内容。不需要懂技术、不要资金、不要人力投入、借助熊猫,任何人都可以轻松成为一个大站的站长。
8、行业垂直搜索引擎
利用熊猫采集,配合熊猫采集配套的分词索引检索系统,用户就可以轻松构建一个行业垂直搜索引擎。例如招聘、人才、房产、旅游、购物、商务、分类信息、二手、医疗健康等等。
熊猫采集软件,从开发伊始,就是为了做通用搜索引擎而设计,如果仅仅认为熊猫只是原始而廉价的采集软件,那就是对熊猫大误解。熊猫采集的技术,是源于熊猫精准搜索引擎。
9、作为相关软件的功能配套
可以作为舆情、监控、情报等互联网相关软件的配套软件,节约重复高成本开发,关键是可以提高用户的使用体验,提升软件自身的技术形象。
技术特点
1、搜索引擎解析内核
熊猫利用的是搜索引擎的智能解析内核,实现对网页内容的仿浏览器解析、分解、内容提取、近似页面比对等等。
2、内置分词/索引/检索引擎
软件内置有熊猫独立研发的分词索引检索引擎,用于文章的分词、文章内容相似度的分析匹配,摘要自动生成等应用。性能强悍,内存占用小,效率极高。
3、视觉模拟技术
熊猫采集软件会模拟人的视觉来分析网页,在此基础上利用参考(模板)页面实现采集匹配工作。
4、网站页面逻辑关系分析技术
这是熊猫特有的原创技术。是熊猫采集软件所依赖的基础技术之一。
特别说明
测试账号:test 密码:123456- 数据爬虫采集软件
- 数据采集软件
-
 更多 (11个) >>电脑爬虫软件大全 在互联网信息时代,很多朋友们都会选择在网上收集自己需要的信息,想要快速的收集各种信息的话,就需要使用到相关爬虫工具了,通过爬虫软件我们就可以自动收集自己想要的数据信息,能够节约大量的手动时间,但是爬虫软件有哪些呢?小编今天就在此给大家提供了电脑爬虫软件大全,包括Python、杰灵采集器、火车头采集器等等,这里面的软件都是操作十分简单的,不需要用户会相关的技术就能够直接操作,无论是老手还是新手都适用,对此有兴趣的小伙伴们可以来下载体验。
更多 (11个) >>电脑爬虫软件大全 在互联网信息时代,很多朋友们都会选择在网上收集自己需要的信息,想要快速的收集各种信息的话,就需要使用到相关爬虫工具了,通过爬虫软件我们就可以自动收集自己想要的数据信息,能够节约大量的手动时间,但是爬虫软件有哪些呢?小编今天就在此给大家提供了电脑爬虫软件大全,包括Python、杰灵采集器、火车头采集器等等,这里面的软件都是操作十分简单的,不需要用户会相关的技术就能够直接操作,无论是老手还是新手都适用,对此有兴趣的小伙伴们可以来下载体验。 -
-

杰灵采集器 2.76M
查看/简体中文v20190708官方版 -

火车头采集器 54.03M
查看/简体中文v10.24官方版 -

Editor Tools全自动无人值守采集软件 19.17M
查看/简体中文v3.6.9官方版 -

深维全能信息采集软件 2.25M
查看/简体中文v2.5.3.9官方版 -

善肯网页TXT采集器 896K
查看/简体中文v1.0绿色版 -

网页信息收集器 1.04M
查看/简体中文v1.0绿色版 -

捷豹数据采集软件 3.01M
查看/简体中文v1.0.0.1官方版 -

BalanceLink(数据采集工具) 10.91M
查看/简体中文v4.1.1官方版 -

熊猫智能采集软件 12.04M
查看/简体中文v3.5 -

Python最新版 25.09M
查看/简体中文v3.12.1 -

News File Grabber(新闻文件抓取器) 1.42M
查看/简体中文v4.6.0.4官方版
-
发表评论
0条评论软件排行榜
热门推荐
 xclient最强版 v2.0最新版750K / 简体中文
xclient最强版 v2.0最新版750K / 简体中文 FocusMe(网站拦截器) 官方版32.32M / 简体中文
FocusMe(网站拦截器) 官方版32.32M / 简体中文 winsock expert 抓包工具 v0.7绿色汉化版473K / 简体中文
winsock expert 抓包工具 v0.7绿色汉化版473K / 简体中文 阿呆喵广告拦截工具 绿色版4.25M / 简体中文
阿呆喵广告拦截工具 绿色版4.25M / 简体中文 局域网抢网速软件 v2.0.7附使用说明2.55M / 简体中文
局域网抢网速软件 v2.0.7附使用说明2.55M / 简体中文 Tcpdump(数据抓包工具) v4.9.0官方版1.15M / 英文
Tcpdump(数据抓包工具) v4.9.0官方版1.15M / 英文 蓝蛇端口扫描器(端口扫描工具) v2.7.0.590官方版4.49M / 简体中文
蓝蛇端口扫描器(端口扫描工具) v2.7.0.590官方版4.49M / 简体中文 MACAddressView(MAC地址搜索工具) v1.35汉化绿色版850K / 简体中文
MACAddressView(MAC地址搜索工具) v1.35汉化绿色版850K / 简体中文 NetTraffic流量监控软件 v1.59.2绿色免费版385K / 英文
NetTraffic流量监控软件 v1.59.2绿色免费版385K / 英文 爱快流控软路由 v3.6.13官方版38.6M / 简体中文
爱快流控软路由 v3.6.13官方版38.6M / 简体中文
 赣公网安备36010602000168号,版权投诉请发邮件到ddooocom#126.com(请将#换成@),我们会尽快处理
赣公网安备36010602000168号,版权投诉请发邮件到ddooocom#126.com(请将#换成@),我们会尽快处理