

网页信息收集器是一款绿色小巧,功能实用的网页信息采集软件。Internet上有着极其庞大的资源信息,各行各业的信息无所不有,网页信息收集器可以很方便的针对某个网站的信息内容进行收集。如某个论坛的所有注册会员的E-MAIL列表、某个行业网站的企业名录、某个下载网站上所有软件列表等等。操作简单方便,更容易为普通用户所掌握,有需求的用户不妨下载体验!
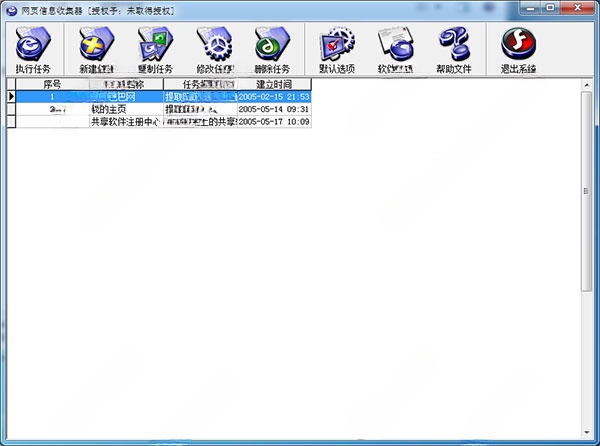
根据已建立的任务信息保存、提取网页,也可通过“双击”某项任务启动此功能
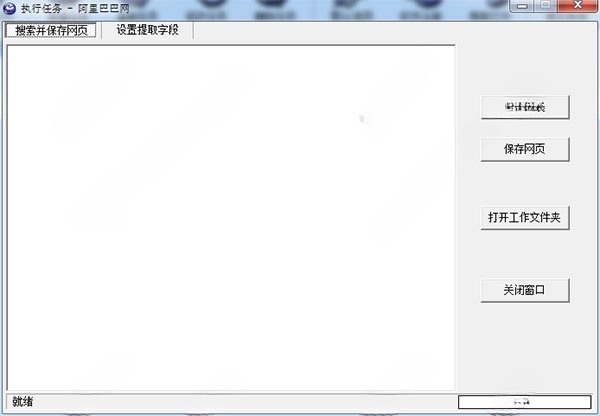
2、新建、复制、修改、删除任务
新建、复制、修改、删除任务信息
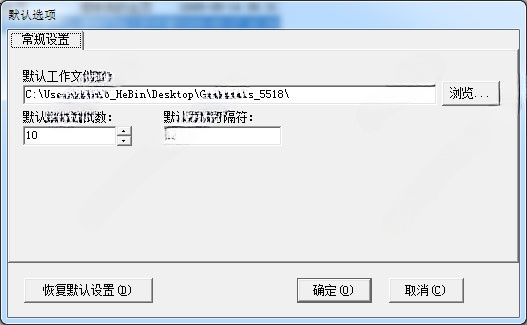
3、默认选项
设置默认工作路径(默认为当前程序目录下的WorkDir文件夹)
设置默认提取测试数 (默认为10)
设置默认文本分隔符 (默认为 *)
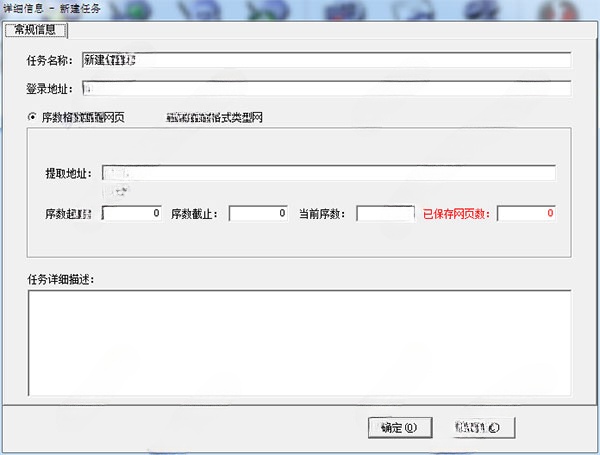
4、新建、编辑任务信息
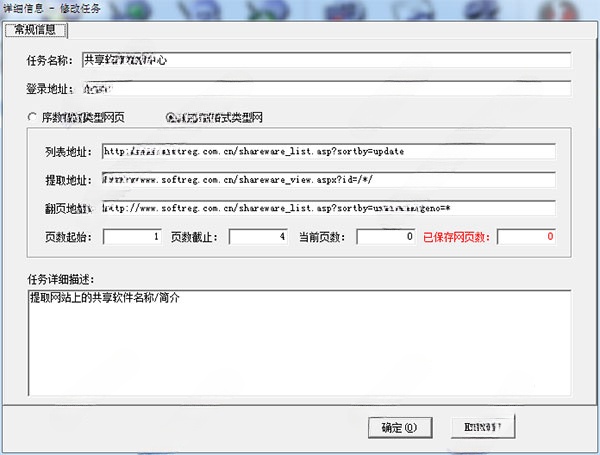
任务名称:在默认的工作文件夹下生成以此命名的文件夹。
登录地址:针对某些需要登录才能查看其网页内容的网站,填写登录页面地址。在执行任务时,软件会打开此登录页面让您登录该网站
序数格式类型网页、非序数格式类型网:
这里的序数格式、非序数格式主要是指提取地址是否仅仅是数字的变化。例如类似于:
①http://xxx.com/1.html 和 http://xxx.com/2.html 就属于序数格式
②http://xxx.com/abc.html 和 http://xxx.com/def.html 则属于非序数格式
列表地址:在类型为“非序数格式类型网”时,第一页列表的链接地址
提取地址:由实际保存的网页地址共同部分 + * 号组成。
例如要提取:
①http://xxx.com/1.html 和 http://xxx.com/2.html 则提取地址为 http://xxx.com/*.html
②http://abc.xxx.com/abc.html 和 http://test.xxx.com/def.html 则提取地址为 http://*.xxx.com/*.html
翻页地址:为列表网页上的“下一页”链接地址,将其中变化的部分用 * 号代替。
页数起始:要开始提取的页数
页数截止:要停止提取的页数
当前页数:当前已经提取到的页数
已保存网页数:已经保存的网页数
任务详细描述:该任务的详细描述信息
收起介绍展开介绍

功能特色
1、执行任务根据已建立的任务信息保存、提取网页,也可通过“双击”某项任务启动此功能

2、新建、复制、修改、删除任务
新建、复制、修改、删除任务信息

3、默认选项
设置默认工作路径(默认为当前程序目录下的WorkDir文件夹)
设置默认提取测试数 (默认为10)
设置默认文本分隔符 (默认为 *)

4、新建、编辑任务信息
任务名称:在默认的工作文件夹下生成以此命名的文件夹。
登录地址:针对某些需要登录才能查看其网页内容的网站,填写登录页面地址。在执行任务时,软件会打开此登录页面让您登录该网站
序数格式类型网页、非序数格式类型网:
这里的序数格式、非序数格式主要是指提取地址是否仅仅是数字的变化。例如类似于:
①http://xxx.com/1.html 和 http://xxx.com/2.html 就属于序数格式
②http://xxx.com/abc.html 和 http://xxx.com/def.html 则属于非序数格式
列表地址:在类型为“非序数格式类型网”时,第一页列表的链接地址
提取地址:由实际保存的网页地址共同部分 + * 号组成。
例如要提取:
①http://xxx.com/1.html 和 http://xxx.com/2.html 则提取地址为 http://xxx.com/*.html
②http://abc.xxx.com/abc.html 和 http://test.xxx.com/def.html 则提取地址为 http://*.xxx.com/*.html
翻页地址:为列表网页上的“下一页”链接地址,将其中变化的部分用 * 号代替。
页数起始:要开始提取的页数
页数截止:要停止提取的页数
当前页数:当前已经提取到的页数
已保存网页数:已经保存的网页数
任务详细描述:该任务的详细描述信息

- 数据爬虫采集软件
-
 更多 (11个) >>电脑爬虫软件大全 在互联网信息时代,很多朋友们都会选择在网上收集自己需要的信息,想要快速的收集各种信息的话,就需要使用到相关爬虫工具了,通过爬虫软件我们就可以自动收集自己想要的数据信息,能够节约大量的手动时间,但是爬虫软件有哪些呢?小编今天就在此给大家提供了电脑爬虫软件大全,包括Python、杰灵采集器、火车头采集器等等,这里面的软件都是操作十分简单的,不需要用户会相关的技术就能够直接操作,无论是老手还是新手都适用,对此有兴趣的小伙伴们可以来下载体验。
更多 (11个) >>电脑爬虫软件大全 在互联网信息时代,很多朋友们都会选择在网上收集自己需要的信息,想要快速的收集各种信息的话,就需要使用到相关爬虫工具了,通过爬虫软件我们就可以自动收集自己想要的数据信息,能够节约大量的手动时间,但是爬虫软件有哪些呢?小编今天就在此给大家提供了电脑爬虫软件大全,包括Python、杰灵采集器、火车头采集器等等,这里面的软件都是操作十分简单的,不需要用户会相关的技术就能够直接操作,无论是老手还是新手都适用,对此有兴趣的小伙伴们可以来下载体验。 -
-

杰灵采集器 2.76M
查看/简体中文v20190708官方版 -

火车头采集器 54.03M
查看/简体中文v10.24官方版 -

Editor Tools全自动无人值守采集软件 19.17M
查看/简体中文v3.6.9官方版 -

深维全能信息采集软件 2.25M
查看/简体中文v2.5.3.9官方版 -

善肯网页TXT采集器 896K
查看/简体中文v1.0绿色版 -

网页信息收集器 1.04M
查看/简体中文v1.0绿色版 -

捷豹数据采集软件 3.01M
查看/简体中文v1.0.0.1官方版 -

BalanceLink(数据采集工具) 10.91M
查看/简体中文v4.1.1官方版 -

熊猫智能采集软件 12.04M
查看/简体中文v3.5 -

Python最新版 25.09M
查看/简体中文v3.12.1 -

News File Grabber(新闻文件抓取器) 1.42M
查看/简体中文v4.6.0.4官方版
-
发表评论
0条评论软件排行榜
热门推荐
 蜂巢数据(网页采集软件) v1.6官方版20.71M / 简体中文
蜂巢数据(网页采集软件) v1.6官方版20.71M / 简体中文 轻松点网页自动确定工具 v1.0.1官方版855K / 简体中文
轻松点网页自动确定工具 v1.0.1官方版855K / 简体中文 网站关键字监控工具 v6.6官方版18.32M / 简体中文
网站关键字监控工具 v6.6官方版18.32M / 简体中文 Linkman书签管理工具 v8.9.96.86M / 简体中文
Linkman书签管理工具 v8.9.96.86M / 简体中文 xpath helper插件 v2.0.2官方版251K / 简体中文
xpath helper插件 v2.0.2官方版251K / 简体中文 chrome身份验证器插件 v4.18官方版240K / 简体中文
chrome身份验证器插件 v4.18官方版240K / 简体中文 readability网页插件 v3.0.15官方版318K / 英文
readability网页插件 v3.0.15官方版318K / 英文 MySmartPrice v2.1官方版160K / 简体中文
MySmartPrice v2.1官方版160K / 简体中文 ScreenOFF v1.6官方版422K / 简体中文
ScreenOFF v1.6官方版422K / 简体中文 流量精灵 v6.6.2绿色版26.8M / 简体中文
流量精灵 v6.6.2绿色版26.8M / 简体中文
 赣公网安备36010602000168号,版权投诉请发邮件到ddooocom#126.com(请将#换成@),我们会尽快处理
赣公网安备36010602000168号,版权投诉请发邮件到ddooocom#126.com(请将#换成@),我们会尽快处理